京東商品信息采集實踐 以圖書類商品頁為例
在當今數字化時代,電商平臺的數據采集已成為市場分析、競品研究和用戶行為洞察的重要手段。以京東平臺為例,其商品信息采集不僅限于簡單的價格和庫存監控,更可深入挖掘商品詳情、用戶評論及銷售動態。本文將以京東圖書類商品頁為例,探討如何高效采集商品信息,并簡要對比新聞信息采集的異同。
一、京東圖書商品信息采集的關鍵要素
京東圖書商品頁包含豐富的信息,采集時需重點關注以下內容:
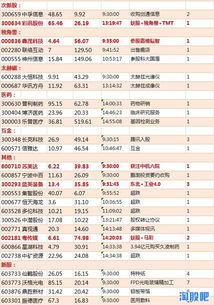
- 基礎商品信息:如圖書標題、作者、出版社、ISBN、出版日期、定價和折扣價等。這些數據可用于價格跟蹤和庫存分析。
- 商品詳情與描述:包括圖書簡介、目錄、編輯推薦及內容摘要,這些文本信息有助于內容分析和關鍵詞提取。
- 用戶生成內容:用戶評論、評分和問答環節是寶貴的反饋來源,可通過情感分析評估產品口碑。
- 銷售與促銷數據:如銷量排名、促銷活動(如滿減、優惠券)、物流信息(如配送時效),這些數據可輔助銷售策略制定。
- 關聯信息:例如同類圖書推薦、作者其他作品,可幫助構建產品關聯網絡。
采集方法通常涉及網絡爬蟲技術,使用Python工具如Requests和BeautifulSoup解析HTML頁面,或通過京東開放API(如有權限)獲取結構化數據。需要注意的是,采集過程應遵守京東的Robots協議,避免過度請求導致IP被封,并確保數據使用符合相關法律法規。
二、新聞信息采集的對比與應用
新聞信息采集與商品信息采集在目標和方法上存在異同。相似之處在于,兩者都依賴網絡爬蟲或API從網頁提取數據,且需處理文本、圖片等多媒體內容。新聞采集更注重時效性和來源多樣性,例如從多家媒體網站抓取頭條新聞、發布時間和作者信息,并可能涉及自然語言處理技術進行事件檢測和主題分類。
在京東圖書采集案例中,數據相對結構化,易于解析;而新聞采集常面臨動態內容(如JavaScript渲染)和反爬蟲機制的挑戰。新聞信息采集更強調實時性,例如監控突發新聞,而商品信息則更關注價格和庫存的周期性變化。
三、總結與建議
無論是京東商品信息采集還是新聞信息采集,核心在于明確目標、選擇合適工具,并遵守倫理與法律邊界。對于圖書類商品,采集數據可應用于市場趨勢分析、個性化推薦系統或庫存管理;而新聞采集則服務于輿情監控或內容聚合。在實際操作中,建議采用增量采集策略以節省資源,并定期更新采集規則以應對網站結構變化。通過合理利用這些數據,企業和研究者可提升決策效率,驅動業務增長。
如若轉載,請注明出處:http://m.vzuvc.cn/product/19.html
更新時間:2026-01-08 07:33:16